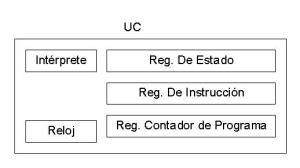
Se presenta a continuación un esquema en bloques de un sistema básico de un computador y sus funciones esenciales, ALU ( Arithmetic Logic Unit), unidad de control, unidad de I/O y memoria central. Todos los demás componentes agregados al sistema se denominan periféricos , y vinculan al sistema con el mundo exterior, para intercambiar y visualizar datos.
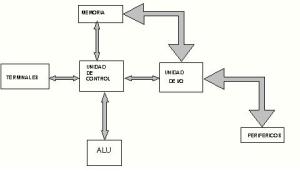
Los datos introducidos en el computador se utilizan como base para operaciones de todo tipo, aritméticas, lógicas, Son funciones realizadas por la ALU que además contiene registros especiales y de uso general donde procesa la información antes y después de su uso. Luego será almacenada en la memoria central , que es la zona de almacenamiento de gran capacidad, se guardan aquí tanto datos como programas ejecutables.
Todo el sistema es controlado por la unidad de control que genera las señales temporización y sincronización de todo el sistema. A partir de esta breve descripción se pueden apreciar en la arquitectura del sistema dos elementos diferentes en cuanto a sus características; los circuitos eléctricos / electrónicos que constituyen al procesador y lo que se ha dado en llamar el programa ( conjunto de operaciones denominadas instrucciones. Los programas a utilizar suelen estar en la memoria central del sistema. Cada una de las celdas que componen la memoria central debe ser seleccionada por la unidad central para poder ordenar la información allí guardada y de esta manera poder transformar los datos en una secuencia determinada para obtener el resultado deseado de la operación de los mismos.
Esta selección se denomina direccionamiento y lo realiza la unidad de control por medio del registro de direccionamiento, y su función es almacenar la dirección a ejecutar del sistema.
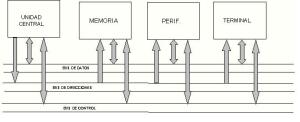
La descripción anterior presenta un tratamiento secuencial de instrucciones que es sincronizado por un reloj ( CLOCK). La comunicación entre la unidad central y el resto del sistema puede realizarse a través de una estructura como la de arriba representada, donde se muestran conjuntos de líneas denominadas bus. Generalmente pueden distinguirse tres indispensables en cualquier tipo de estructura de datos, ellos son datos (data), direcciones(address) y control(control).
FUNCIONAMIENTO DEL MICROPROCESADOR
El microprocesador ejecuta instrucciones almacenadas como números binarios en la memoria principal . La ejecución se puede realizar en varias fases:
PreFetch, Pre lectura de la instrucción desde la memoria principal.
Fetch, envió de la instrucción al decodificador (una parte de la CPU).
Decodificación de instrucción, es decir determinar que instrucción es y por tanto que se debe hacer.
Lectura de operandos (si los hay).
Ejecución de la micro-instrucción.
Escritura de los resultados, primero en el registro acumulador y después en la memoria RAM si fuera necesario.
Cada una de estas fases se realiza en uno o varios ciclos de CPU, dependiendo de la estructura del procesador, y concretamente de su grado de segmentación. La duración de estos ciclos viene determinada por la frecuencia de reloj, y nunca podrá ser inferior al tiempo requerido para realizar la tarea individual (en un solo ciclo) de mayor tiempo. El microprocesador se conecta a un oscilador que genera varios ciclos en un segundo.
Las instrucciones que lee, interpreta y ejecuta el procesador están escritas en su propio lenguaje, el lenguaje-máquina. También se utiliza un lenguaje de más alto nivel el ensamblador. Cada modelo de procesador tiene su propio lenguaje-máquina y necesita su propio ensamblador, es decir, las instrucciones de los AMD e Intel serán distintas.
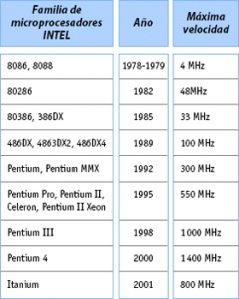
FAMILIAS DE MICROPROCESADORES INTEL
ALU: una unidad aritmética lógica (alu) es un circuito digital que realiza operaciones aritméticas y lógicas operaciones. La alu es un componente fundamental de la unidad central de procesamiento (CPU) de un ordenador, e incluso el más simple microprocesadores contienen una para fines tales como el mantenimiento de los temporizadores. Los procesadores se encuentran dentro de las modernas CPU y unidades de procesamiento gráfico (gpu) acomodar alu muy potente y muy complejo, de un solo componente puede contener un número de alus.
La unidad de punto flotante: realizan las operaciones sobre los números decimales. Estas unidades suelen ser más complejas y por lo tanto necesitan de más área dentro del micro. Esto es lo que ha llevado a AMD a integrar solo una cada dos núcleos en su arquitectura CMT.
Funciones de la UC
–Lectura de las instrucciones (fetching).
–Decodificación de las instrucciones.
–Ejecución de las instrucciones.
–Resolución de situaciones particulares (interrupciones, trampas).
Para ejecutar un programa, la UC va leyendo y ejecutando las instrucciones una por una.
–La ejecución de un programa se compone de una secuencia de ciclos de instrucción.
Unidad de interfaz en el Bus
Es la parte con la cual el microprocesador se comunica con el mundo exterior a través de sus buses y líneas de control, algunas de las operaciones que realiza esta unidad son las siguientes:
· Carga las instrucciones
· Lee las operaciones
· Escribe los resultados
MEMORIA
Los circuitos que permiten almacenar y recuperar la información. En un sentido más amplio, puede referirse también a sistemas externos de almacenamiento, como las unidades de disco o de cinta. Por lo general se refiere sólo al semiconductor rápido de almacenaje (RAM) conectado directamente al procesador.
MEMORIA DE ACCESO ALEATORIO O RAM
En informática, memoria basada en semiconductores que puede ser leída y escrita por el microprocesador u otros dispositivos de hardware. Es un acrónimo del inglés Random Access Memory. Se puede acceder a las posiciones de almacenamiento en cualquier orden.
CACHÉ DE DISCO
En informática, una parte de la memoria de acceso aleatorio de un ordenador o computadora que se reserva para contener, de manera temporal, información leída o escrita recientemente en el disco. La memoria caché de disco realiza distintas funciones: en unos casos, almacena direcciones concretas de sectores; en otros, almacena una copia del directorio y en otros, almacena porciones o extensiones del programa o programas en ejecución
MEMORIA PROGRAMABLE O BORRABLE O DE SÓLO LECTURA O EPROM
En informática, tipo de memoria, también denominada reprogramable de sólo lectura (RPROM, acrónimo inglés de Reprogrammable Read Only Memory). Las EPROM (acrónimo inglés de Erasable Programmable Read Only Memory) son chips de memoria que se programan después de su fabricación. Son un buen método para que los fabricantes de hardware inserten códigos variables o que cambian constantemente en un prototipo, en aquellos casos en los que producir gran cantidad de chips PROM resultaría prohibitivo. Los chips EPROM se diferencian de los PROM por el hecho de que pueden borrarse por lo general, retirando una cubierta protectora de la parte superior del chip y exponiendo el material semiconductor a radiación ultravioleta, después de lo cual pueden reprogramarse.
MEMORIA PROGRAMABLE DE SOLO LECTURA O PROM
En informática, tipo de memoria de sólo lectura (ROM) que permite ser grabada con datos mediante un hardware llamado programador de PROM. Una vez que la PROM ha sido programada, los datos permanecen fijos y no pueden reprogramarse. Dado que las ROM son rentables sólo cuando se producen en grandes cantidades, se utilizan memorias programables de sólo lectura durante las fases de creación del prototipo de los diseños. Nuevas PROM pueden grabarse y desecharse durante el proceso de perfeccionamiento del diseño.
MEMORIA DE SOLO LECTURA O ROM
En informática, memoria basada en semiconductores que contiene instrucciones o datos que se pueden leer pero no modificar. Para crear un chip ROM, el diseñador facilita a un fabricante de semiconductores la información o las instrucciones que se van a almacenar. El fabricante produce entonces uno o más chips que contienen esas instrucciones o datos. Como crear chips ROM implica un proceso de fabricación, esta creación es viable económicamente sólo si se producen grandes cantidades de chips. Los diseños experimentales o los pequeños volúmenes son más asequibles usando PROM o EPROM. El término ROM se suele referir a cualquier dispositivo de sólo lectura, incluyendo PROM y EPROM.
MEMORIA EXPANDIDA
En informática, en los PC de IBM y en los compatibles, organización lógica de memoria, de hasta 8 megabytes (MB) que puede utilizarse en las máquinas que ejecutan MS-DOS en modo real (emulación de 8086). El uso de la memoria expandida está definido en la EMS (Especificación de Memoria Expandida). Como representa la memoria a la que normalmente no acceden los programas que ejecutan MS-DOS, la memoria expandida requiere una interfaz denominada EMM (Gestor de Memoria Expandida), que asigna páginas (bloques) de bytes de la memoria expandida según se necesiten. Sólo el software compatible con EMS puede utilizar la memoria expandida.
MEMORIA EXTENDIDA
En informática, la parte de memoria del sistema que supera 1 megabyte (MB) en las computadoras basadas en procesadores Intel 80286/386/486. Sólo se puede tener acceso a esta memoria cuando el procesador trabaja en modo protegido o en modo virtual real en los equipos 386/486. Normalmente MS-DOS no puede utilizar la memoria extendida. Puede permitirse el acceso a esta memoria mediante la utilización de un determinado software que hace que el microprocesador quede en modo protegido, o mediante el uso de las posibilidades que los procesadores 386 y 486 tienen para asignar determinadas porciones de la memoria expandida como memoria convencional. Para ello se utilizan las convenciones EMS.
BUFFER DE MEMORIA INTERMEDIA
En informática, depósito de datos intermedio, es decir, una parte reservada de la memoria en la que los datos son mantenidos temporalmente hasta tener una oportunidad de completar su transferencia hacia o desde un dispositivo de almacenamiento u otra ubicación en la memoria. Algunos dispositivos, como las impresoras o como los adaptadores que las soportan, suelen tener sus propios buffers.
MEMORIA CACHÉ L2 (Segundo nivel)
Almacena los datos transferidos más recientemente entre la memoria RAM y el microprocesador.
Así, si el microprocesador necesita algo de esta información accede directamente a la caché sin acudir a la RAM. De esta forma acelera la ejecución de las instrucciones del microprocesador ya que la caché trabaja más rápido que la RAM.
REGISTROS
Los registros del procesador se emplean para controlar las instrucciones en ejecución, manejar direccionamiento, y proporcionar capacidad aritmética.
Son direccionables por medio de un nombre, los bits se numeran de derecha a izquierda
Los registros se pueden clasificar como:
Registros de propósito general. Almacenan datos y están disponibles para ser usados por el programador.
Registros de segmento. Estos registros permiten direccionar la memoria.
Apuntador de instrucción. Este es un registro especial que apunta a la siguiente instrucción a ejecutar.
Registros de punto flotante. Como su nombre lo indica estos registros se utilizan para realizar operaciones de punto flotante.
BUSES DE DATOS
El bus es la vía de comunicación para los datos y señales de control en la estructura de un computador, entre la CPU y los diferentes órganos que se le deben poner si se tratan de las pistas o cintas de cobre impresas en la placa principal se llama bus del sistema.
El bus esta formado básicamente por tres: bus de datos ,bus de direcciones y bus de control.
BUS DE DATOS: Es el encargado de transmitir los caracteres.
BUS DE DIRECCIÓN: Es el encargado de direccionar los datos a su origen o destino.
BUS DE CONTROL: Es el encargado de conducir las señales IRQ de solicitud de interrupción que hacen los dispositivos al microprocesador.
BUS DE ESPANCIÓN: Se le llama al conjunto de líneas eléctricas y circuitos electrónicos de control encargados de conectar el bus del sistema de la tarjeta madre con los buses de dispositivos accesorios, tal como una tarjeta controladora de disco, una tarjeta de video y MODEM.
INTERRUPCIONES
Se entiende por interrupciones a los servicios que se ejecutan por medio de una pedido de intervención al funcionamiento del microprocesador y provienen del exterior del sistema. Podemos definir dos tipos fundamentales de interrupciones, de hardware, y de software. Entre las primeras podemos además distinguir, mascarables, no mascarables y del sistema. Todas las interrupciones que pueden intervenir poseen una jerarquía unívoca, ya que dadas las circunstancias pueden producirse dos simultáneamente. Procesadores más popularizados de la línea Intel son:
iAPX 8088/8086
iAPX 80286
iAPX 80386
iAPX 80486
Pentium
UNIDAD DE PUNTO FLOTANTE
Una Unidad de Punto Flotante (Floating Point Unit en inglés) es un componente de la CPU especializado en el cálculo de operaciones en coma flotante. Las operaciones básicas que toda FPU puede realizar son las aritméticas (suma y multiplicación), si bien algunos sistemas más complejos son capaces también de realizar cálculos trigonométricos y/o exponenciales.
No todas las CPUs tienen una FPU dedicada. En ausencia de FPU, la CPU puede utilizar programas en micro código para emular una función en coma flotante a través de la unidad aritmético-lógica (ALU), la cual reduce el coste del hardware a cambio de una sensible pérdida de velocidad.
En algunas arquitecturas, las operaciones en coma flotante se tratan de forma completamente distinta a las operaciones enteras, con registros dedicados y tiempo de ciclo diferentes. Incluso para operaciones complejas, como la división, podrían tener un circuito dedicado a dicha operación.
Hasta mediados de la década de los 90 del siglo pasado, era común que las CPU no incorporasen una FPU en los ordenadores domésticos, sino que eran un elemento opcional conocido como coprocesador. Ejemplos podrían ser las FPUs 387 y 487 que se utilizaban en las CPUs 386 y 486SX (el modelo 486DX ya incluía el coprocesador de serie) en máquinas Pentium, o la FPU 68881 utilizada en las CPUs 680×0 en ordenadores Macintosh. Sin embargo, a partir de dichas CPUs, la FPU se convirtió en un elemento común presente en la mayoría de procesadores domésticos (series Pentium y PowerPC en adelante.
UNIDAD DE INTERFAZ EN EL BUS
La unidad de interfaz del bus o unidad E/S, es la parte del procesador que se une con el resto de la PC. Debe su nombre al hecho de que realiza los movimientos de datos hacia el bus de datos del procesador, el primer conducto en la transferencia de información hacia y desde el CPU. La BIU es la responsable de responder a todas las señales que van al procesador, y de generar todas las señales que van del procesador a las demás partes del sistema. También sirve de paso a las instrucciones de programa y los datos para que éstos puedan alcanzar los registros de la unidad de control y de la ALU. La BIU sincroniza los niveles de las señales de la circuitería interna del microprocesador con los de los otros componentes dentro de la PC. Los circuitos internos de un microprocesador, por ejemplo, se diseñan para consumir poca electricidad de modo que puedan funcionar más rápidamente y evitar el calentamiento excesivo. Estos circuitos internos delicados no pueden manejar los voltajes más altos necesarios para los componentes externos. Por lo tanto, cada señal que sale del microprocesador pasa a través de un buffer de señal intermedio en la BIU que incrementa su voltaje.
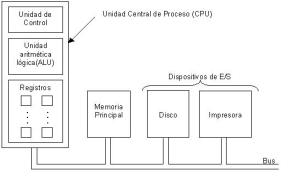
UNIDADES FUNCIONALES BASICAS DE UN MICROPROCESADOR
En la terminología de microprocesadores, a cada grupo de circuitos que desempeñan diferentes tareas importantes se les denomina «unidad funcional», y el conjunto de unidades funcionales y la forma como están interconectadas se denomina «arquitectura» del microprocesador.
Las unidades básicas de un microprocesador son:
- Unidad Aritmético/Lógica: Conocida también como ALU (Arithmetic/Logic Unit.). La ALU es la parte del microprocesador que lleva a cabo las operaciones aritméticas y lógicas en los datos binarios. Algunas de ellas se aplican sobre dos operandos, otras solamente en uno.
- Unidad de Control: Es la unidad funcional primaria dentro del microprocesador. Utiliza señales de reloj para mantener la secuencia de eventos apropiada para llevar a cabo cualquier tarea de procesamiento.
- Registros Internos: Son unidades de almacenamiento temporal dentro de la CPU. Algunos tienen usos específicos, otros son de uso general.
- Memoria del Programa: Es una ROM o EPROM que contiene el programa del microprocesador. En algunos casos, la memoria del programa también almacena parámetros o tablas de datos que no sufren modificaciones.
Hay otras unidades funcionales que también pueden existir en el microprocesador; como son la «memoria de datos» y los «puertos de entrada/salida». La unidad de procesamiento central (CPU) es un microprocesador que posee únicamente las tres unidades básicas: unidad de control, unidad aritmético/lógica y algunos registros.
UNIDAD DE INTERFAZ EN EL BUS
El Bus de Datos: Es un conjunto de líneas bidireccionales, que transportan información del microprocesador hacia la memoria o puertos y de estos al microprocesador.
El Bus de Direcciones: Es unidireccional, por el solamente circula información proveniente del microprocesador.
Bus de Control: Lo conforman la sincronización y el sentido de transferencia de información en el bus de datos, y el tipo de transferencia indicada por medio de señales de control originadas en el CPU.
Bus Internos: Son buses que existen dentro del microprocesador que sirven para comunicar entre sí a la ALU, los registros internos y la unidad de control.
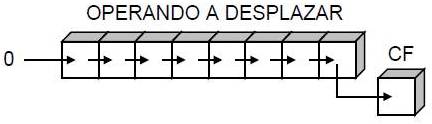
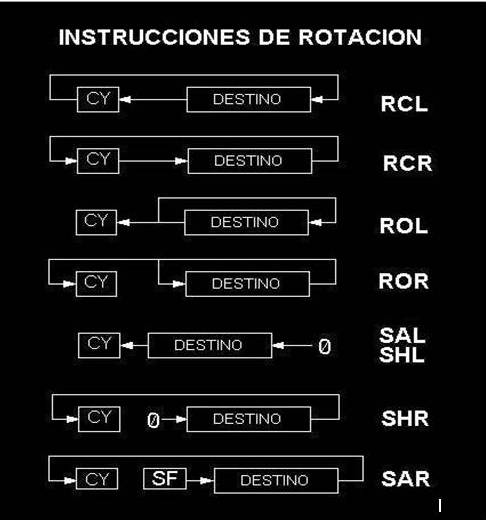
INSTRUCCIONES DEL PROCESADOR
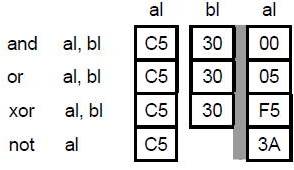
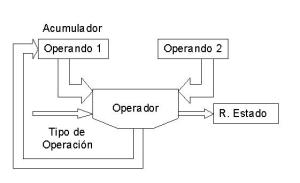
Aritméticas: es la encargada de realizar los cálculos. Los datos sobre los que se realizan la operaciones se denominan operandos. Al elemento encargado de ejecutar las operaciones se le denomina operador, y está formado por una serie de circuitos electrónicos que son capaces de sumar dos números binarios o hacer las operaciones lógicas elementales: disyunción, conjunción y negación; incluso algunos operadores son también capaces de multiplicar, dividir y realizar otras operaciones más complejas.
Lógica: es el cerebro de una computadora. Su función e ejecutar programas almacenados en la memoria central tomando sus instrucciones, examinándolas y luego ejecutándolas una tras otra. La CPU se compone de varias partes. La unidad de control se encarga de traer las instrucciones de las memoria principal y de determinar su tipo. La unidad aritmética y lógica realiza operaciones como la suma o la función booleana AND, necesarias para llevar a cabo las instrucciones.
Booleanas: Estas instrucciones corresponden a- contactos de cierre: el contacto se establece cuando el objeto bit que controla el contacto está en el estado 1, – contactos de apertura: el contacto se establece cuando el objeto bit que controla el contacto está en el estado 0,- contactos de flanco ascendente: detección del paso de 0 a 1 del objeto bit que lo controla,- contactos de flanco descendente: detección del paso de 1 a 0 del objeto bit que lo controla.
PIPELINING
La segmentación de instrucciones es similar al uso de una cadena de montaje en una fábrica de manufacturación. En las cadenas de montaje, el producto pasa a través de varias etapas de producción antes de tener el producto terminado. Cada etapa o segmento de la cadena está especializada en un área específica de la línea de producción y lleva a cabo siempre la misma actividad. Esta tecnología es aplicada en el diseño de procesadores eficientes. A estos procesadores se les conoce como pipeline processors.
Un pipeline processor está compuesto por una lista de segmentos lineales y secuenciales en donde cada segmento lleva a cabo una tarea o un grupo de tareas computacionales. Puede ser representado gráficamente en dos dimensiones, en donde en el eje vertical encontramos los segmentos que componen el pipeline y en el segmento horizontal representamos el tiempo.
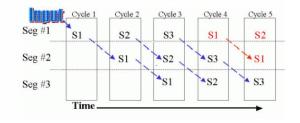
Hay tres aspectos importantes que deben ser considerados en pipeline . Lo primero que debemos observar es que el trabajo es dividido en piezas que más o menos ajustan dentro de los segmentos que componen el pipeline . Segundo, para que el pipeline trabaje de forma eficiente es necesario que las particiones de trabajo tomen aproximadamente la misma cantidad de tiempo. De no ser así, el segmento que requiera más tiempo ( T ) hará que el pipeline se retrase y cada segmento requerirá T unidades de tiempo para completar su trabajo. Esto quiere decir que los segmentos rápidos estarán mucho tiempo ociosos. Tercero, para que el pipeline funcione adecuadamente, deben ocurrir pocas excepciones o hazards (riesgos) que puedan causar retardos o errores en el pipeline . En caso de ocurrir errores, la instrucción tiene que ser cargada nuevamente en el pipeline y se debe reiniciar la misma instrucción que ocasionó la excepción.

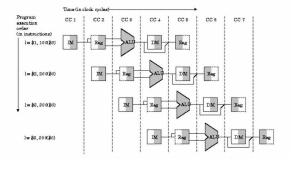
Riesgos en el pipeline Los procesadores con pipeline presentan una serie de problemas conocidos como hazards, y que pueden ser de tres tipos:
- Riesgos Estructurales: Ocurren cuando diversas instrucciones presentan conflictos cuando tratan de acceder a la misma pieza de hardware. Este tipo de problema puede ser aliviado teniendo hardware redundante que evitan estas colisiones. También se pueden agregar ciertas paradas ( stall ) en el pipeline o aplicar reordenamiento de instrucciones para evitar este tipo de riesgo.
- Riesgos de Datos: ocurren cuando una instrucción depende del resultado de una instrucción previa que aún está en el pipeline y cuyo resultado aún no ha sido calculado. La solución más fácil es introducir paradas en la secuencia de ejecución pero esto reduce la eficiencia del pipeline.
- Riesgos de Control: Son resultado de las instrucciones de salto que necesitan tomar una decisión basada en un resultado de una instrucción mientras se están ejecutando otras.
RAM Y ROM
La memoria de acceso aleatorio (en inglés: random-access memory cuyo acrónimo es RAM) es la memoria desde donde el procesador recibe las instrucciones y guarda los resultados. Es el área de trabajo para la mayor parte del software de un computador.1 Existe una memoria intermedia entre el procesador y la RAM, llamada caché, pero ésta sólo es una copia (de acceso rápido) de la memoria principal (típicamente discos duros) almacenada en los módulos de RAM.1 Por ejemplo, en el sistema operativo Windows Vista, gracias al servicio ReadyBoost, es posible asignar memoria flash de un dispositivo externo USB como memoria caché y así mejorar la velocidad del equipo informático, debido a la mayor velocidad de las Flash respecto al disco duro.

Se trata de una memoria de estado sólido tipo DRAM en la que se puede tanto leer como escribir información. Se utiliza como memoria de trabajo para el sistema operativo, los programas y la mayoría del software. Es allí donde se cargan todas las instrucciones que ejecutan el procesador y otras unidades de cómputo. Se dicen «de acceso aleatorio» porque se puede leer o escribir en una posición de memoria con un tiempo de espera igual para cualquier posición, no siendo necesario seguir un orden para acceder a la información de la manera más rápida posible.

La Memoria ROM nace por esta necesidad, con la característica principal de ser una memoria de sólo lectura, y por lo tanto, permanente que sólo permite la lectura del usuario y no puede ser reescrita.
Por esta característica, la Memoria ROM se utiliza para la gestión del proceso de arranque, el chequeo inicial del sistema, carga del sistema operativo y diversas rutinas de control de dispositivos de entrada/salida que suelen ser las tareas encargadas a los programas grabados en la Memoria ROM. Estos programas (utilidades) forman la llamada Bios del Sistema.